Datamining
Datamining
Datamining (dolování z dat) je sada automatizovaných postupů pro nalézání dosud neznámých vzorů a vztahů ve velkých databázích. Zastřešuje širokou škálu technik používaných v řadě odvětví. Rozvoj začal počátkem 90. let 20. století u bank specializovaných na kreditní karty, rozšířil se do pojišťovnictví, veřejných služeb, zásilkových služeb, energetiky, maloobchodu a dalších.
Datamining je analytický krok procesu KDD (Knowledge Discovery in Databases). Stojí na průsečíku tří disciplín: strojové učení + statistika + správa databází.
Souvisí s: fuzzy-logika, neuronové sítě, evoluční algoritmy, optimalizace.
Cíle dataminingu
- Zvýšení zisku — identifikace nových zákazníků a příležitostí
- Snížení nákladů — efektivnější cílení a alokace zdrojů
- Snížení rizika ztrát — odhalení rizikových zákazníků, predikce odchodu
- Správný výrobek → správný zákazník → správné místo → správný čas
Praktické aplikace
- Bankovnictví: Fraud detection, credit scoring, churn prediction, segmentace zákazníků
- Pojišťovnictví: Detekce podvodných pojistných událostí, optimalizace pojistných sazeb
- Retail: Market basket analysis (Amazon), doporučovací systémy, rozmístění zboží
- Energetika/průmysl: Prediktivní údržba, optimalizace spotřeby
Proces práce s daty — CRISP-DM
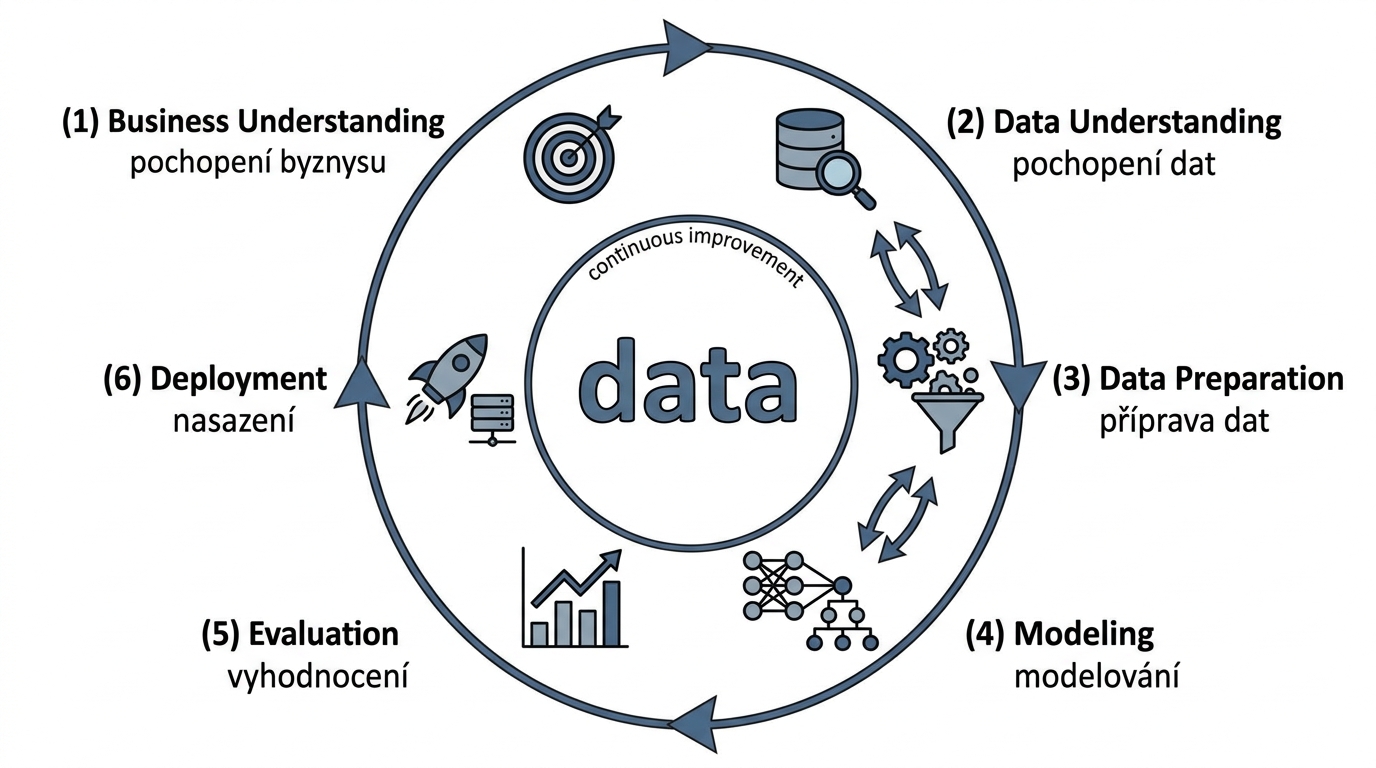
CRISP-DM (Cross-Industry Standard Process for Data Mining) je nejrozšířenější metodika — průzkumy ukazovaly 3–4× vyšší využití než konkurence.
Business Understanding → Data Understanding → Data Preparation
↑ ↓
Deployment ← Evaluation ← Modeling ← (iterativně zpět)
| Fáze | Obsah | Poznámka |
|---|---|---|
| 1. Business Understanding | Definice cílů, obchodní otázka, kritéria úspěchu | |
| 2. Data Understanding | Sběr dat, průzkum, kvalita, vhodnost pro analýzu | |
| 3. Data Preparation | Čištění, klasifikace, vzorkování, sumarizace, transformace | 50–80 % celkového úsilí |
| 4. Modeling | Výběr a aplikace technik, kalibrace parametrů | Nejkratší, ale nejviditelnější |
| 5. Evaluation | Ověření vůči obchodním cílům, metriky přesnosti | |
| 6. Deployment | Nasazení do produkce, monitoring, finální zpráva |
Proces je iterativní — z každé fáze se lze vracet zpět.
Klíčové techniky dataminingu
Link analýza (Analýza vazeb)
Technika zaměřená na vyhodnocování vztahů (vazeb) mezi entitami v síti, místo studia vlastností jednotlivých entit.
Princip: Data jako graf — uzly = entity (osoby, účty, produkty), hrany = vztahy nebo interakce.
Typy přístupů:
- Heuristické — rozhodovací pravidla z odborných znalostí
- Šablonové — zpracování nestrukturovaných dat
- Podobnostní — vážené skórování atributů
- Statistické — lexikální statistika
Příklady použití:
- Fraud detection — odhalování fraud rings (překrývající se adresy, telefony u různých žadatelů)
- AML (Anti-Money Laundering) — praní peněz
- FBI ViCAP — propojování trestných činů
- Google PageRank — hodnocení stránek podle příchozích odkazů
- Sociální sítě — detekce komunit, šíření vlivu, doporučení přátel
Historický vývoj:
- Generace (1975): Ruční maticové grafy
- Generace: Automatizované nástroje (IBM i2 Analyst's Notebook)
- Generace: Automatická vizualizace napojená na datové zdroje
Klastrování (Clustering)
Definice: Unsupervised learning — rozdělení dat do skupin (clusterů/shluků) tak, aby objekty uvnitř skupiny byly si co nejpodobnější a objekty z různých skupin co nejodlišnější. Kategorie předem neznáme — algoritmus je hledá sám.
K-means algoritmus
Minimalizuje: WCSS (Within-Cluster Sum of Squares) — vnitřní varianci clusterů.
Kroky:
- Inicializace — náhodně zvolit k centroidů (moderní: k-means++)
- Přiřazení — každý bod přiřadit do nejbližšího centroidu (Euklidovská vzdálenost)
- Aktualizace — přepočítat centroidy jako průměr přiřazených bodů
- Opakování — dokud se přiřazení stabilizuje nebo max. iterace
Při různých spuštěních může dávat různé výsledky → doporučuje se spustit vícekrát.
Výběr počtu clusterů k:
- Elbow method — vynést WCSS vs. k, hledat „loket"
- Silhouette analysis — jak dobře bod pasuje do svého vs. sousedního clusteru (hodnoty 0–1)
- Gap statistic — porovnání se vzdáleností náhodných dat
- Davies-Bouldin Index — nižší = lepší; Calinski-Harabasz Index — vyšší = lepší
Hierarchické klastrování
Vytváří dendrogram — stromovou strukturu zobrazující postupné slučování clusterů.
Přístupy:
- Agglomerativní (zdola nahoru) — každý bod = vlastní cluster, postupně slučovat
- Divisivní (shora dolů) — jeden velký cluster, postupně dělit
Metody výpočtu vzdálenosti (linkage):
- Ward — minimalizuje nárůst SSE; clustery ≈ stejné velikosti; nejčastěji doporučovaná
- Complete — vzdálenost = maximum mezi body
- Average — vzdálenost = průměr
Čtení dendrogramu: Hledat nejdelší vertikální úsečku nepřerušenou horizontálou — tam nakrájíme strom. Počet clusterů = počet průsečíků řezné linie s dendrogramem.
Rozhodovací stromy (Decision Trees)
Definice: Model klasifikující data pomocí hierarchického větvení. Každý vnitřní uzel = test atributu; každá větev = výsledek testu; každý list = výsledná třída nebo hodnota.
Míry nečistoty uzlu
Entropie:
H(S) = −Σ pᵢ × log₂(pᵢ)
- H = 0 → čistý uzel (vše jedné třídy)
- H = 1 → maximální smíšenost (binární, 50/50)
Informační zisk (Information Gain):
Gain(S, A) = H(S) − Σ (|Sᵥ| / |S|) × H(Sᵥ)
Vybíráme atribut A s nejvyšším informačním ziskem.
Giniho index (Gini Impurity):
Gini(S) = 1 − Σ pᵢ²
- Gini = 0 → čistý uzel
- Gini = 0,5 → maximální nečistota (binární)
Gini je výpočetně jednodušší (bez logaritmů) — prakticky dávají podobné výsledky.
Algoritmy rozhodovacích stromů
| Algoritmus | Metrika | Vlastnosti |
|---|---|---|
| ID3 | Informační zisk (entropie) | Pouze kategorická data, bez prořezávání |
| C4.5 | Gain ratio (normalizovaný) | Spojité proměnné, chybějící hodnoty, prořezávání |
| CART | Giniho index | Binární stromy, klasifikace i regrese, prořezávání |
Prořezávání (pruning): Stromy mají tendenci přetrénovat se (overfitting). Pruning odstraňuje statisticky nevýznamné větve.
Asociační pravidla — Apriori algoritmus
Hledá vzory souvýskytu v databázích transakcí. Typicky: market basket analysis — které produkty se kupují společně.
Formát pravidla: {A} → {B} — „kdo koupí A, koupí i B"
Klíčové metriky
Support (podpora):
Support(A) = počet transakcí s A / celkový počet transakcí
Confidence (důvěra):
Confidence(A → B) = Support(A ∪ B) / Support(A)
Lift:
Lift(A → B) = Confidence(A → B) / Support(B)
- Lift = 1 → A a B jsou nezávislé
- Lift > 1 → pozitivní asociace (A zvyšuje pravděpodobnost B)
- Lift < 1 → negativní asociace
Princip Apriori
Anti-monotone property: Pokud množina A nesplňuje min. support, žádná její nadmnožina nemůže být frekventovaná → efektivní prořezávání prostoru hledání.
Postup:
- Nastavit min_sup a min_conf
- Najít frekventované 1-itemsety
- Generovat kandidáty (k+1)-itemsetů z frekventovaných k-itemsetů
- Prořezat nesplňující min_sup
- Opakovat; pak generovat pravidla splňující min_conf
Witness Miner / Lanner Group
Lanner Group Ltd — softwarová společnost, Birmingham (UK), 1996. Specializace na simulační software.
WITNESS — diskrétní simulační software od 1986. Integrován v produktech Oracle, SAP, IBM. Umožňuje:
- Modelování podnikových procesů a výrobních operací
- 3D modelování, diskrétní a stochastická simulace
- Integraci s MS Excel, MS Access, ODBC, CAD
Witness Miner — označení pro integraci process mining technik (Disco/Fluxicon) se simulačním nástrojem WITNESS.
Funkce analýzy ze simulačních dat:
- Závislosti vstupů a výstupů — jaké kombinace vstupních parametrů vedou k jakým výstupům
- Pravidla — extrakce rozhodovacích pravidel z chování simulovaného systému
- Shluky (clustery) — seskupení podobných scénářů výsledků simulace
- Statistiky/KPI — exportovatelné do Excel
WITNESS Optimizer — využívá Simulated Annealing a Tabu Search pro optimalizaci parametrů.
Poznámka: Specifický modul "Witness Miner" není podrobně zdokumentován veřejně — pravděpodobně proprietární terminologie nebo starší funkce. Viz evoluční algoritmy pro principy SA a Tabu Search.
MATLAB pro datamining
MATLAB nabízí funkce v rámci Statistics and Machine Learning Toolbox.
Klastrování
kmeans — k-means:
[idx, C] = kmeans(data, k);
% idx = přiřazení bodů; C = centroidy (k×p matice)
% S vizualizací:
[idx, C] = kmeans(data, 2);
gscatter(data(:,1), data(:,2), idx);
hold on;
plot(C(:,1), C(:,2), 'kx', 'MarkerSize', 15, 'LineWidth', 3);
linkage + dendrogram — hierarchické klastrování:
Z = linkage(data, 'ward'); % vytvoří hierarchickou strukturu
dendrogram(Z); % vizualizace
clusters = cluster(Z, 'maxclust', 4); % řez na 4 clustery
Rozhodovací stromy
fitctree — trénování:
Mdl = fitctree(X_train, Y_train);
view(Mdl, 'Mode', 'graph'); % vizualizace stromu
resubLoss(Mdl) % přesnost na trénovacích datech
predict — predikce:
YPred = predict(Mdl, X_test);
accuracy = sum(YPred == Y_test) / numel(Y_test);
fprintf('Přesnost: %.2f%%\n', accuracy * 100);
Prevence overfittingu:
Mdl = fitctree(X, Y, 'MaxNumSplits', 10); % omezení hloubky
Mdl = fitctree(X, Y, 'MinLeafSize', 5); % min. vzorků v listu
Přehled technik pro zkoušku
| Technika | Co dělá | Klíčové pojmy |
|---|---|---|
| Link analýza | Hledá vazby v síti entit | Graf, uzly, hrany, fraud detection |
| K-means | Seskupuje podobné objekty | Centroid, WCSS, Elbow method, k |
| Hierarchické klastrování | Stromová struktura podobnosti | Dendrogram, Ward, linkage |
| Rozhodovací stromy | Klasifikace větvícím se stromem | Entropie, informační zisk, Gini, ID3/C4.5/CART |
| Asociační pravidla | Vzory souvýskytu | Support, Confidence, Lift, Apriori |
| CRISP-DM | Standardní proces projektu | 6 fází, iterativní |
| WITNESS/Lanner | Simulace + process mining | Diskrétní simulace, KPIs, Optimizer |
Kontrolní otázky ke zkoušce
- Čím se zabývá datamining?
- Jak jsou data získávána?
- Jak jsou data zpracovávána?
- K čemu nám slouží datamining?
- Co znamená Link analýza?
- K čemu slouží klastrování?
- K čemu slouží a co je to rozhodovací strom?
- Jak lze využít programu MATLAB v dataminingu?
- K čemu slouží program Witness Miner?
Pojmy k zapamatování
Datamining, zpracování dat, MATLAB, Witness Miner, závislosti vstupů a výstupů, volba pravidel, shluky, statistické charakteristiky.
Zdroje v kurzu IpmrK
- Kniha — definice, shrnutí, kontrolní otázky, pojmy
- Techniky a nástroje — CRISP-DM, Link analýza, k-means, rozhodovací stromy, Apriori, Witness Miner, MATLAB kód (Wikipedia, GeeksforGeeks, IBM, Lanner)