Měření rizika — statistické charakteristiky
Měření rizika — statistické charakteristiky
Rozptyl σ²
Definice:
kde:
- — i-tá hodnota výnosu (či jiné finanční proměnné, např. ceny akcie, kurzu)
- — střední hodnota (očekávaný výnos),
- — pravděpodobnost i-té hodnoty (nebo pro empirické rozdělení z historických dat)
- — počet pozorování
Rozptyl měří kvadratickou odchylku od průměru. Kvadratický tvar má tři důvody: (1) eliminuje znaménka odchylek (zisky a ztráty se nevykrátí), (2) silněji penalizuje větší odchylky, (3) má příjemné matematické vlastnosti (aditivita pro nezávislé veličiny).
Jednotka: kvadrát původní jednotky (Kč², %²) — nepraktické pro interpretaci, proto se v praxi používá σ.
Směrodatná odchylka σ
Definice:
- Stejné jednotky jako (Kč, %, atd.) — proto interpretačně použitelná.
- Praktická interpretace: typická odchylka výnosu (či ceny) od průměru.
- Pro normální rozdělení platí pravidlo 68–95–99,7 %: 68 % pozorování leží v intervalu , 95 % v , 99,7 % v .
Grafická interpretace
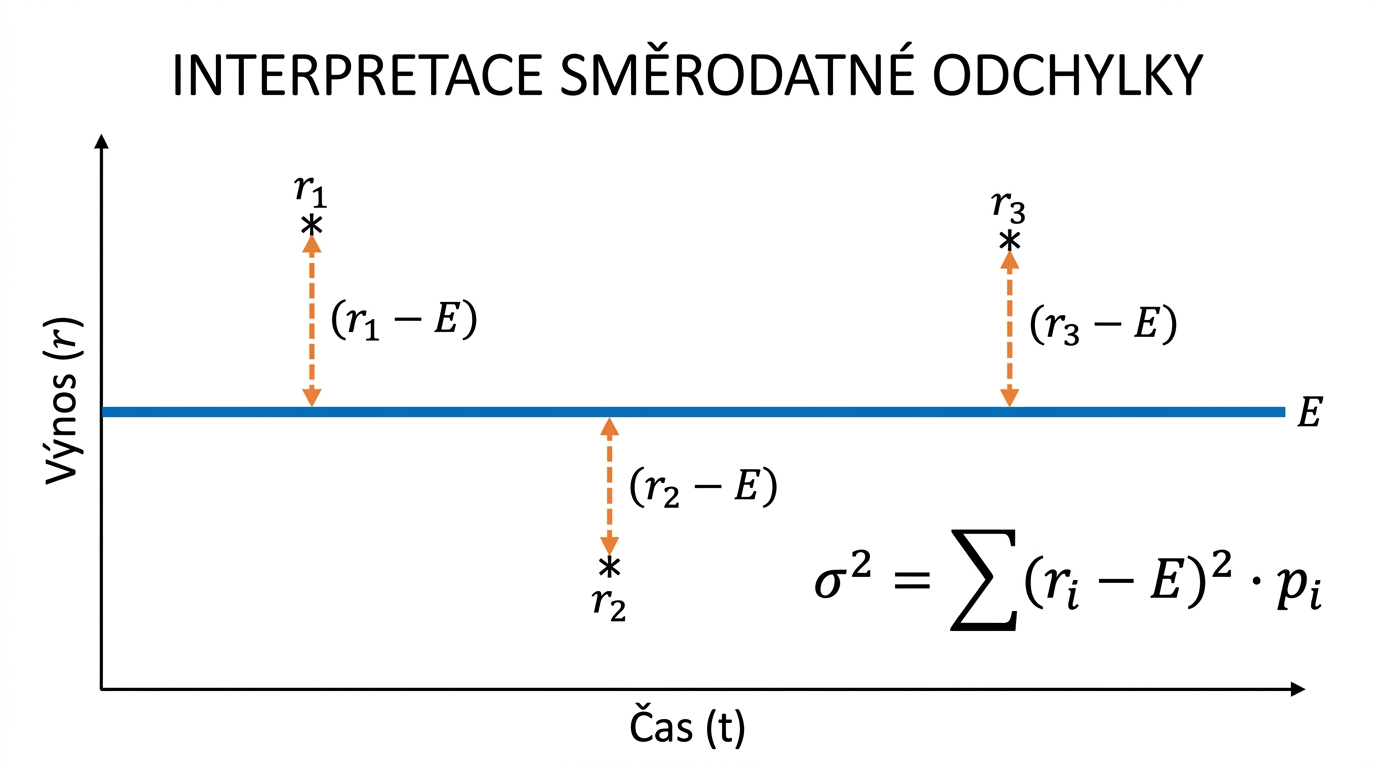
Na časové řadě je vodorovná linie střední hodnoty (očekávaný výnos / průměrná cena). Body jsou jednotlivé pozorované hodnoty. Vertikální vzdálenosti jsou jednotlivé odchylky:
- Sčítají se kvadraticky (na druhou) → výsledek je .
- Nezáleží na tom, jestli je odchylka kladná (nad linií) nebo záporná (pod linií) — kvadrát ji vždy učiní kladnou.
- Vyšší rozptyl bodů kolem E = vyšší σ = vyšší volatilita = vyšší riziko.
- Aktivum, jehož ceny leží těsně u E, je nízkorizikové; aktivum s body rozptýlenými daleko od E je vysoce rizikové.
Příklad: akcie ČS
Konkrétní výpočet :
- Cena akcie ČS: 179,14 Kč (střední hodnota )
- Směrodatná odchylka: σ ≈ 8,95 Kč (≈ 5 % z ceny)
- Výpočet proveden z empirického rozdělení historických cen.
Interpretace:
- Typická odchylka ceny od střední hodnoty 179,14 Kč je ±8,95 Kč.
- V intervalu 170,19 – 188,09 Kč by se mělo nacházet zhruba 68 % pozorování (za předpokladu normálního rozdělení).
- Riziková expozice: investice 1 000 000 Kč do této akcie znamená typický pohyb hodnoty portfolia ±50 000 Kč. Investor s tímto údajem může nastavit stop-loss limit, kapitálovou rezervu nebo se rozhodnout pro hedging.
Koeficient variace KV
Definice:
Vlastnosti:
- Bezrozměrný (resp. v procentech) — umožňuje srovnání rizik různě velkých aktiv.
- Vyšší KV = vyšší relativní riziko na jednotku výnosu.
- Řeší limit σ: srovnání σ = 10 Kč pro akcii za 200 Kč a σ = 10 Kč pro dluhopis za 10 000 Kč by bylo zavádějící — KV ukáže, že akcie je padesátkrát rizikovější.
Příklad — akcie ČS: σ = 8,95 Kč, E = 179,14 Kč → KV = 8,95 / 179,14 ≈ 5 %.
Srovnání: státní dluhopis se σ = 0,5 Kč a E = 1 000 Kč → KV = 0,05 %. Akcie ČS je tedy ve smyslu KV přibližně 100× rizikovější než státní dluhopis, ačkoli σ se liší jen 18× — relativní pohled mění obrázek dramaticky.
Praktický postup výpočtu
1. Sběr historických hodnot r₁, r₂, ..., r_n.
(Časová řada cen / výnosů z databáze nebo tržních dat.)
2. Výpočet střední hodnoty:
E(r) = (1/n) · Σ r_i
3. Výpočet rozptylu:
σ² = (1/n) · Σ (r_i − E)²
Pozn.: pro výběrový rozptyl se dělí (n−1), pro populační n.
4. Výpočet směrodatné odchylky:
σ = √σ²
5. Výpočet koeficientu variace:
KV = σ / E(r) (případně · 100 % pro vyjádření v procentech)
Populační vs. výběrový rozptyl: pokud máme celý soubor (všechna pozorování), používá se dělitel — populační rozptyl. Pokud pracujeme s náhodným výběrem z větší populace a chceme nezkreslený odhad, používá se dělitel (Besselova korekce) — výběrový rozptyl. Pro velká je rozdíl zanedbatelný; v Excelu odpovídají funkce VAR.P (populační) a VAR.S (výběrový).
Tabulka klasifikace rizik podle KV
Orientační hodnoty pro klasifikaci aktiva podle relativního rizika:
| KV (%) | Klasifikace |
|---|---|
| < 5 % | Velmi nízké |
| 5–15 % | Nízké |
| 15–30 % | Střední |
| 30–50 % | Vysoké |
| > 50 % | Velmi vysoké, spekulativní |
Omezení statistických charakteristik
Statistické charakteristiky mají několik důležitých předpokladů a slabin, které je nutné si uvědomit:
- Předpoklad normálního rozdělení. σ je optimální popis variability pro Gaussovo rozdělení. Reálné finanční výnosy mají často tlusté konce (fat tails) — extrémní události jsou pravděpodobnější, než předpovídá normální rozdělení. σ pak podhodnocuje skutečné riziko.
- Symetrie. σ stejně váží zisky i ztráty. Pro investora je ale klíčový jen ztrátový směr. Pro asymetrická aktiva (opce, strukturované produkty) jsou vhodnější metriky VaR (Value at Risk), CVaR (Conditional VaR) nebo semivariance (jen ztrátová strana).
- Stacionární předpoklad. σ se počítá z minulých dat. Pokud se režim trhu změní (krize 2008, COVID 2020, geopolitické šoky, nová regulace), historická σ podhodnocuje budoucí riziko.
- Černé labutě (Nassim Taleb zdrojové prezentace). σ ze své podstaty neumí zachytit ojedinělé katastrofické události — události s extrémně nízkou pravděpodobností a extrémně vysokým dopadem leží mimo doménu klasické statistiky. Pro tyto případy je nutný stresový test, scénářová analýza nebo opční hedging.
Vztah měření a mapy rizik
- σ a KV poskytují kvantitativní vstup pro mapu rizik (osy pravděpodobnost × dopad). Pravděpodobnost překročení určitého ztrátového limitu se odvodí z rozdělení (např. při normálním rozdělení).
- V praxi se kombinuje kvantitativní (σ, KV, VaR) a kvalitativní hodnocení (5-stupňové škály typu "1 = nepatrné, 5 = katastrofální").
- Pro nekvantifikovatelná rizika (reputační, právní, regulatorní) chybí historická data — tam se používá pouze kvalitativní mapa s odhadem expertů.
Použití v PERT
V síťové analýze projektu (PERT — Program Evaluation and Review Technique) se rozptyl používá pro odhad nejistoty trvání jednotlivých aktivit:
kde:
- — optimistický odhad trvání aktivity
- — pesimistický odhad trvání aktivity
- — nejpravděpodobnější odhad (vstupuje do očekávaného trvání , ale ne do σ²)
Rozptyl celého projektu je součtem rozptylů aktivit ležících na kritické cestě. Z toho lze odvodit pravděpodobnost, že projekt skončí do plánovaného termínu (cross-link sitova-analyza-cpm-pert).
Souvislosti
- definice-rizika — kvalitativní pohled na riziko (pravděpodobnost × dopad), který σ a KV kvantifikují.
- mapa-rizik — vizualizace pravděpodobnost × dopad; σ poskytuje kvantitativní polohu na osách.
- klasifikace-rizik — KV slouží jako vstup pro klasifikaci aktiva do rizikových kategorií.
- sitova-analyza-cpm-pert — PERT využívá σ² aktivit pro odhad rozptylu celkového trvání projektu na kritické cestě.
- Cross-course:
- fuzzy-logika (ipmrk) — alternativa pro popis nejistoty, která se nedá vyjádřit pravděpodobnostně (lingvistické proměnné).
- predikce (ipmrk) — predikce budoucí volatility (např. pomocí neuronových sítí nebo modelů typu GARCH) jako vstup pro σ.
Navigace
- Předchozí: definice-rizika
- Navazující: analyza-rizik-proces
- Související: mapa-rizik, klasifikace-rizik